【Python | Tkinter | Beautifulsoup】スクレイピングアプリ(最終回)

PythonとBeautifulsoupを使った、Webスクレイピングツールの最終回は、Tkinterで作成したGUIに指定日を入力すると、
その日に投稿された記事を取得しExcelに入力するツールの完成形です。
前回の「Webサイトから取得した情報をExcelに自動入力する機能の実装編」をまだ見ていない方は、
先にこちらから見ていただくと分かりやすいと思います。
完成形
実際にスクレイピングツールを動かした時の動作はこんな感じです。
GUIに指定日を入力し実行ボタンをクリック、あらかじめ指定されたExcelファイルに
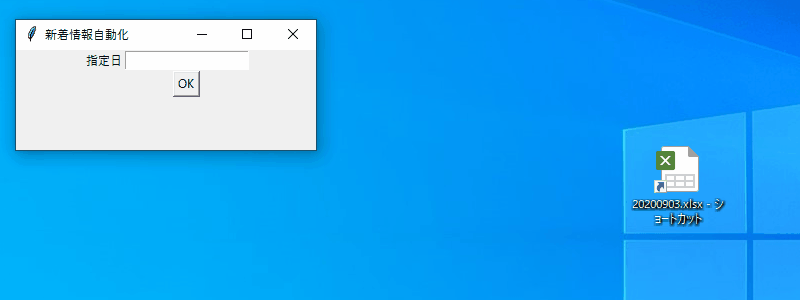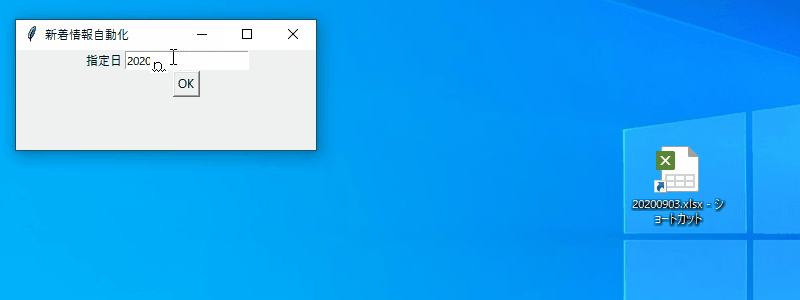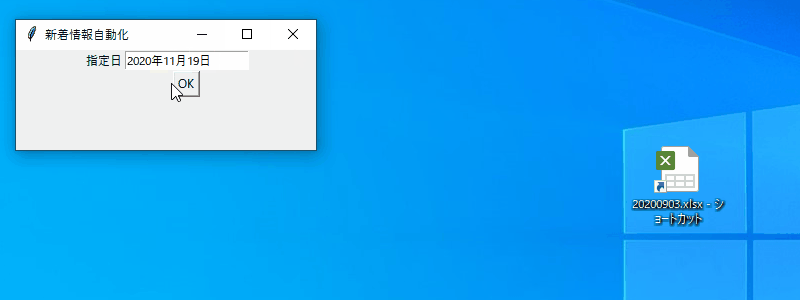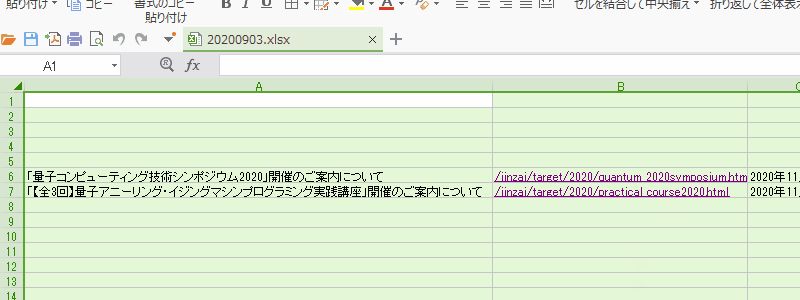
指定日に投稿された記事のタイトルとURLと投稿日が入力されます。
苦労した点
・GUIで入力した指定日を、メソッドに渡す処理がなかなかうまくいかなかった。
・ クラスを別ファイルに分けて作成したが、値の受け渡しがうまくいかず、別ファイルにわけるのは断念。
ソースコードのポイント
・Beautifulesoupで取得したhtmlから、必要な情報が含まれているタグだけを抽出し、
さらに抽出した値から指定日に投稿された記事だけを抽出
# ↓BeautifulsoupでHtmlソース(?)を取得 soup = BeautifulSoup(self.html_data.content, 'html.parser') # ↓(日付けの判定用)Beautiufulsoupで取得した値からタグを指定して抽出 output_days_tag = soup.select("tr") judge = 0 # ↓trタグを取り除いてテキストだけをさらに抽出 for i in output_days_tag: if judge == 0: # 0の時は処理を実行 for a_link in i.select('a'): # jに投稿日を代入 j = i.contents[1].text # 変数jが指定日より大きい間、ループを実行 if j > target_day: continue # 変数jが指定日を一致したら、一致した日の記事タイトルとURLを取得 elif j == target_day: self.target_news_title.append(i.contents[3].text) self.target_news_url.append(a_link.get('href')) # 上記以外になったら、変数judgeに1を代入し、処理を終了 else: judge = 1 break else: break
judge = 0以降の判定の処理は、if judge == 0がTrueのあいだ処理を実行し、
次の行のfor a_link in i.select('a')内で記事投稿日と指定日を比較し、両値が一致したタイミングで、
記事のタイトルとURLを取得するような処理にしました。 もっと他にいい方法があると思うのですが、今はこれが精いっぱい( ;∀;)
ソースコード
苦労した点でも書きましたが、最初はクラスは別ファイルに記載してモジュールとしてインポートして使う想定でしたが、
何度試してもうまくいかなかったので、1ファイルにまとめる方向に妥協しました。。
#!usr/bin/python # -*- coding: UTF-8 -*- import tkinter import requests from bs4 import BeautifulSoup from datetime import datetime import openpyxl import re # 取得した情報を書き込むファイルを指定 target_file = "20200903.xlsx" # ファイルの保存先のパス filepath = r"C:/Users/USER/Documents/" # ↓収集したデータをExcelに入力するクラス class ExcelInput: def excelwrite(self, target_news_title, target_url, target_day ): # ↓データを入力するExcelファイルを指定してインスタンス化 book = openpyxl.load_workbook(filepath + target_file) # ↓指定したExcelファイルに存在するシート名を指定してインスタンス化 sheet = book['input_date'] # ↓取得した情報の入力開始行を指定 i = 6 # ↓セルに値が入っている場合、次の行を指定 while sheet.cell(column=1, row=i).value != None: i += 1 # ↓リストのtarget_url[]の値を指定する変数 j = 0 # ↓収集したニュースタイトル数だけ処理を実行するループ for tnt in target_news_title: # 1列目にニュースタイトル sheet.cell(column=1, row=i).value=tnt # 2列目にニュースURL sheet.cell(column=2, row=i).value=target_url[j] # 3列目に指定日 sheet.cell(column=3, row=i).value=target_day i += 1 j += 1 book.save(r"C:/Users/USER/Documents/" + target_file) # ↓Webサイトから情報を取得するクラス class webget: def __init__(self): self.target_news_title = [] self.target_news_url = [] def webaccess(self, url, target_day): self.target_url = url # URLを格納する変数 self.html_data = '' # サイトから取得したhtmlソースを格納する変数 self.news_url = '' # ↓引数で渡されたURLにアクセスし、responseオブジェクトを取得 self.html_data = requests.get(self.target_url) # ↓BeautifulsoupでHtmlソース(?)を取得 soup = BeautifulSoup(self.html_data.content, 'html.parser') # ↓(日付けの判定用)Beautiufulsoupで取得した値からタグを指定して抽出 output_days_tag = soup.select("tr") judge = 0 # ↓trタグを取り除いてテキストだけをさらに抽出 for i in output_days_tag: if judge == 0: # 0の時は処理を実行 for a_link in i.select('a'): # jに投稿日を代入 j = i.contents[1].text # 変数jが指定日より大きい間、ループを実行 if j > target_day: continue # 変数jが指定日を一致したら、一致した日の記事タイトルとURLを取得 elif j == target_day: self.target_news_title.append(i.contents[3].text) self.target_news_url.append(a_link.get('href')) # 上記以外になったら、変数judgeに1を代入し、処理を終了 else: judge = 1 break else: break ei = ExcelInput() ei.excelwrite(self.target_news_title, self.target_news_url, target_day) wg = webget() def btn_click(): # ↓指定日を取得 target_day = dateInputEntry.get() wg.webaccess(r'https://www.ipa.go.jp/about/news/2020.html', target_day) base = tkinter.Tk() # ↓GUI画面のサイズ調整 base.geometry('300x100') # ↓GUIのタイトル base.title('新着情報自動化') # ↓GUIのベースに frame = tkinter.Frame(base) frame.pack() # ↓指定日ラベル dateInputLabel = tkinter.Label(frame, foreground='#000000', text="指定日") dateInputLabel.grid(row=2, column=0) # 指定日を入力するフォーム dateInputEntry = tkinter.Entry(frame,) dateInputEntry.grid(row=2, column=1) # ボタンを作成 execBtn = tkinter.Button(frame, text="OK", command=btn_click) execBtn.grid(row=3, column=1) base.mainloop()
まとめ
最終的に思ったような動作ができたのですが、ロジックを別ファイルに分けて読み込ませるという点が実現できず妥協してしまったところは、
自分でもまだまだクラス系の知識が足りていないところだと痛感しました。
関数やクラスの理解度を上げないとダメですね(>_<) これからも精進します!