【Python | Beautifulsoup】スクレイピングアプリ(第2回) 取得した情報をExcelに自動入力

PythonとBeautifulsoupを使った、Webスクレイピングツールを作成する第2回目は、Webサイトから取得した情報をExcelに自動入力する機能の追加です。
第1回目で作成したWebから情報を取得する記事をまだ見ていない方は、先にこちらから見ていただくことで流れがつかめると思います。
最近「作業の自動化」関連の本を書店でもよく見かけるようになりました。それだけ、今注目度が高い自動化ですが、Python × Excelで検索すると、作業自動化の情報が豊富に出てくるあたり、PythonとExcelは相性がいいんだなってひしひし感じますね(^^♪
作るもの
・Webサイトから、前日に投稿されたニュース記事のタイトルとURLを取得し、Excelに自動入力するツール
機能要件
・Webサイトから必要な情報を取得
★取得した情報をExcelに書き込み
・情報を書き込むExcelファイルを選択
今回は、機能要件の2つ目の「取得した情報をExcelに書き込み」の部分を作成していきます。
手動でExcelに情報を入力する工程をイメージすると、
1. 指定したExcelを開く
2. シートを指定する
3. 入力するセルにマウスカーソルを合わせる
4. 入力する
これらの工程を自動化するため、プログラムを組んでいきます。
プログラムを組む前に、openpyxlを少し勉強
openpyxlは、PythonでExcelを操作するためのモジュールで、Excelのファイルやシート、セルなどを指定して処理を実行できます。
使い方はこんな感じです。
★Excelファイルの読み込みは以下のように記述します。
openpyxl.load_workbook(ファイル名.xlsx)
★シートを指定する場合は、インスタンス化します。
excel_book['sheet名']
★セルの指定は、row(行)、column(列)で指定できます。
sheet.cell(row=5, column=6)
ソースコード
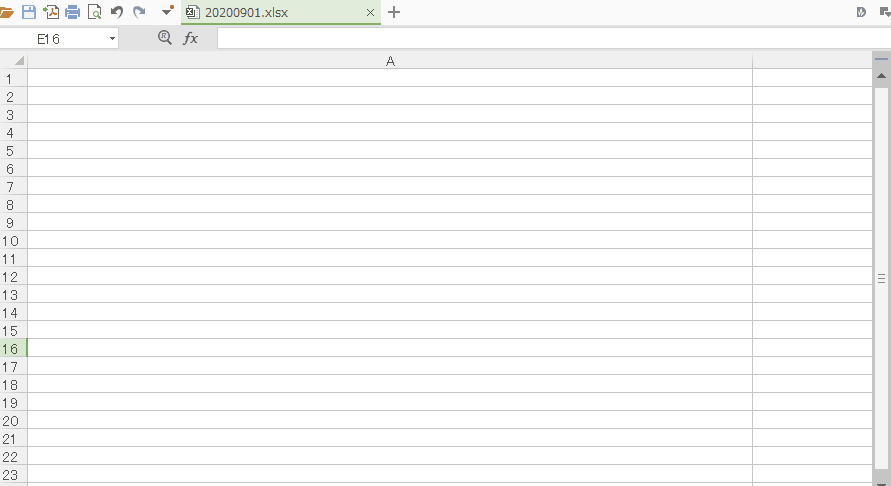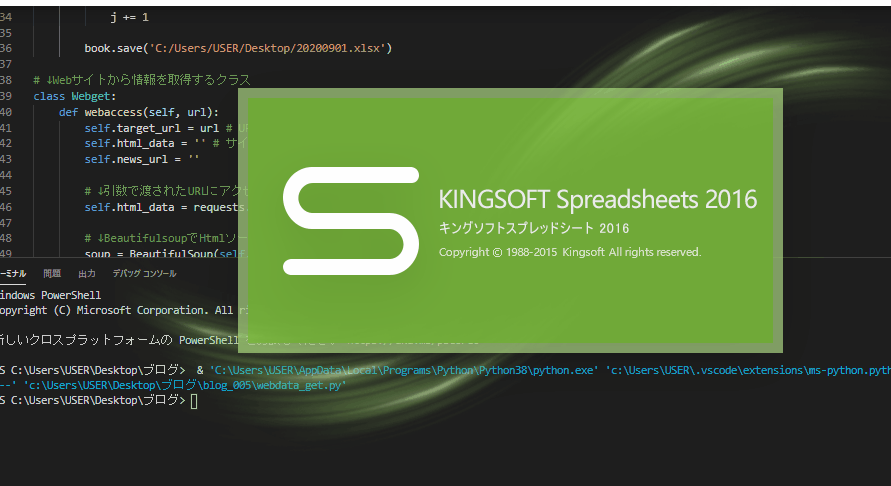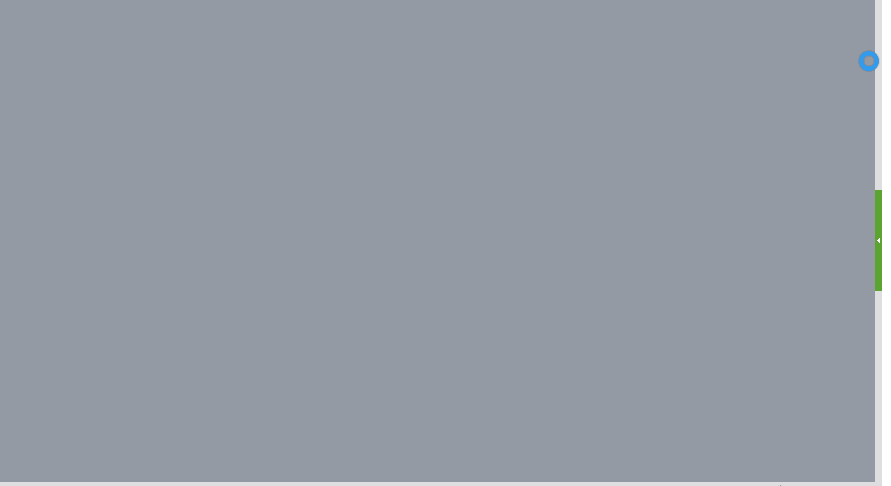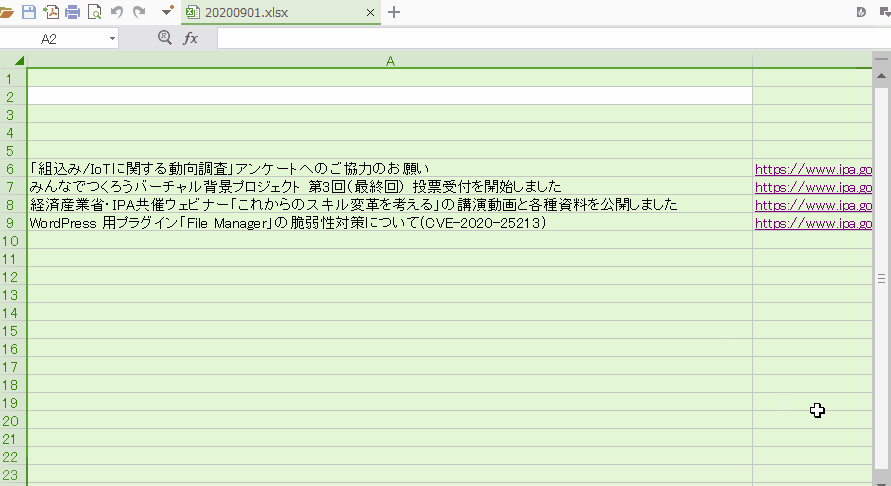
Webから取得した情報をExcelに入力するクラスを追加しました。今回苦労した点は、一つ目のサイトから取得した値をExcelに入力した後、二つ目のサイトから取得した値を追加する際、すでに値があるセルに上書きされてしまったため、空のセルを見つけるまでセルをチェック処理を組むのが、かなり大変でした。。
#!usr/bin/python # -*- coding: UTF-8 -*- import requests from bs4 import BeautifulSoup from datetime import datetime import openpyxl target_day = "2020年9月18日" # ↓収集したデータをExcelに入力するクラス class ExcelInput: def excelwrite(self, target_news_title, target_url, target_day ): # ↓データを入力するExcelファイルを指定してインスタンス化 book = openpyxl.load_workbook('C:/Users/USER/Desktop/20200901.xlsx') # ↓指定したExcelファイルに存在するシート名を指定してインスタンス化 sheet = book['input_date'] # ↓値を入力する行を指定する変数 i = 6 # ↓値を入力するセルが空かどうか判定 while sheet.cell(column=1, row=i).value != None: i += 1 # ↓リストのtarget_url[]の値を指定する変数 j = 0 # ↓収集したニュースタイトル数だけ処理を実行するループ for tnt in target_news_title: sheet.cell(column=1, row=i).value=tnt sheet.cell(column=2, row=i).value=target_url[j] sheet.cell(column=3, row=i).value=target_day i += 1 j += 1 book.save('C:/Users/USER/Desktop/20200901.xlsx') # ↓Webサイトから情報を取得するクラス class Webget: def webaccess(self, url): self.target_url = url # URLを格納する変数 self.html_data = '' # サイトから取得したhtmlソースを格納する変数 self.news_url = '' # ↓引数で渡されたURLにアクセスし、responseオブジェクトを取得 self.html_data = requests.get(self.target_url) # ↓BeautifulsoupでHtmlソース(?)を取得できる認識です soup = BeautifulSoup(self.html_data.content, 'html.parser') # ↓(日付けの判定用)Beautiufulsoupで取得した値からタグを指定して抽出 output_days_tag = soup.select("th") # ↓タグを取り除いてテキストだけをさらに抽出 output_days = [i.text for i in output_days_tag] # ↓欲しい値-タイトル(タグあり) news_title_tag = soup.select("td a") # ↓タイトル(タグ無し) news_title = [i.text for i in news_title_tag] # ↓URLの取得 news_url = [i["href"] for i in news_title_tag] target_news_title = [] target_url = [] i = 0 # ↓ループ処理でニュース投稿日を変数'r'に追加 for r in output_days: # ↓ニュース投稿日が指定日と一致するか判定 if r == target_day: # ↓一致する場合、リストにタイトルとURLを取得 target_news_title.append(news_title[i]) url = news_url[i] # ↓URLが'http'で始まっているか判定 if url.startswith("http"): target_url.append(url) # ↓'http'で始まらない場合は、付与 else: target_url.append("https://www.ipa.go.jp" + url) i += 1 # ↓ニュース投稿日が指定日より後か判定 elif r > target_day: i += 1 continue else: break ei = ExcelInput() ei.excelwrite(target_news_title, target_url, target_day) wg = Webget() wg.webaccess(r'https://www.ipa.go.jp/about/news/2020.html') wg.webaccess(r'https://www.ipa.go.jp/security/announce/alert.html')
解説
今回は業務で使うExcelを想定し、6行目から取得した値を入力したかったのでi = 6とし、for文でループして6、7、8・・・とデータを入力していくようにコードを書きました。前述でも書きましたが、一つ目のWebサイトから取得した値は、ループで順に行を変えて入力できたのですが、二つ目のWebサイトで取得した値をExcelに入力する場合、変数 iが初期値の6に戻るため、一つ目の値が上書きされる現象が発生したため、回避するために、入力する行に値があるか判定する方法として、
while sheet.cell(column=1, row=i).value != None:
とwhile文で、セルがNoneと一致するまで変数 iを1ずつ増やし、空のセルが見つかるまでループをまわしたことで、思った通りの動作を実現できました。
実際のイメージはこちらです。(GIF動画でExcel未入力 → ソース実行 → Excel入力が見れます)